压缩线性 DNG 文件:
DxO PureRAW 6 如何在不影响图像质量的前提下,将 DNG 文件尺寸缩小至大约原文件的四分之一
内容概要
DxO PureRAW 6 为 DNG 格式引入全新的高保真压缩选项。与现有的无损压缩相比,该技术可将文件体积缩减至大约原文件的四分之一,同时在人眼可感知范围内完整保留图像质量。
这一技术结合了两种互补的方法:动态范围压缩(Dynamic Range Compression)以及 JPEG XL 图像编码技术。
核心优势
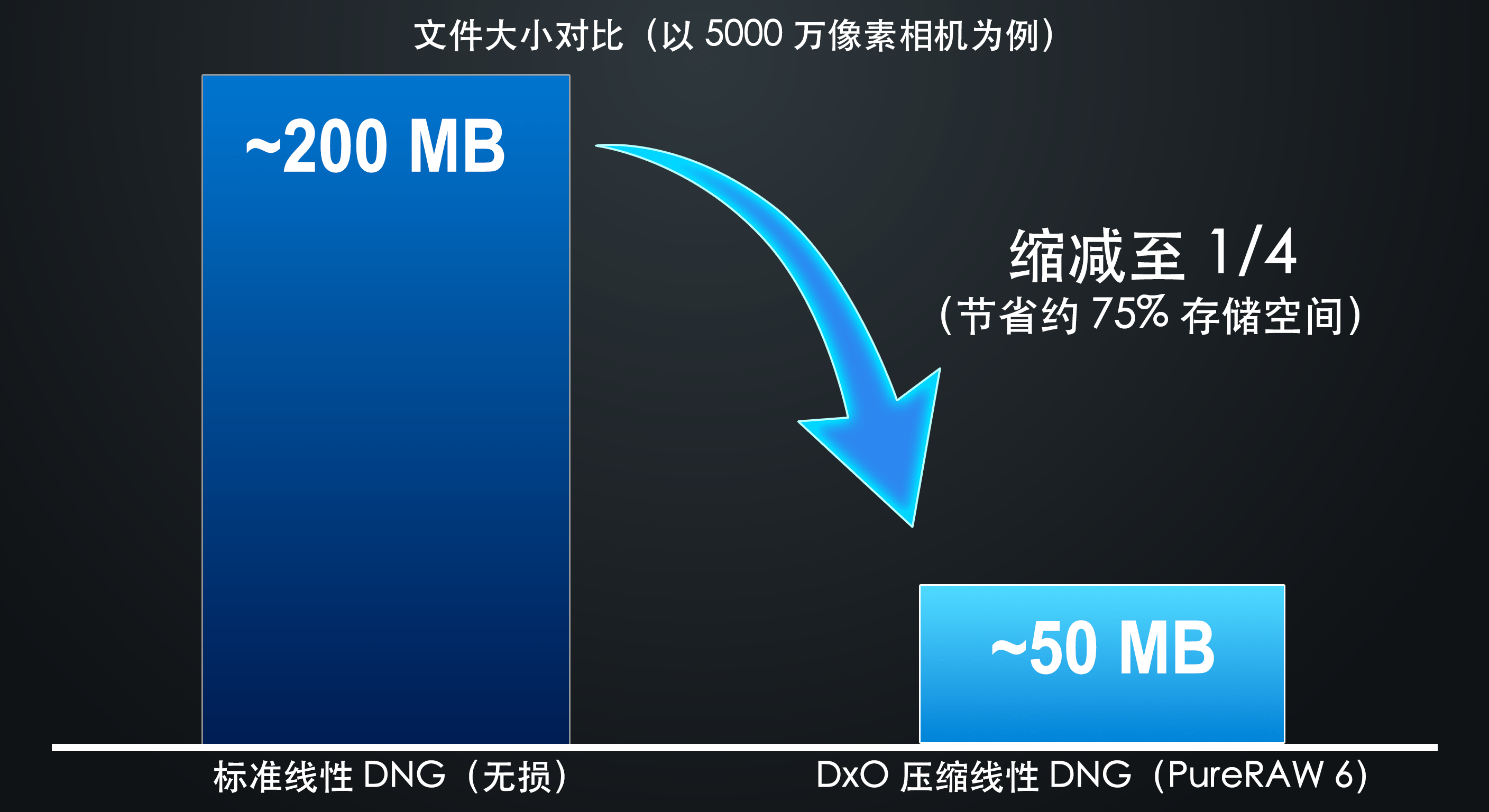
- 文件体积缩小至1/4——以 5000 万像素相机为例,线性 DNG 文件可从约 200 MB 缩减至约 50 MB,使线性 DNG 更适合日常使用及大批量工作流程。 更小的文件意味着更快的导入速度,更快的云端同步,以及更少的磁盘占用。
- 高保真——压缩造成的差异在视觉上几乎不可察觉,即使在大幅度编辑下也能保持稳定的图像表现。
- 兼容性——输出仍为标准 DNG 文件。 任何支持 DNG 的应用程序(如 Adobe Lightroom、Capture One 等)都可正常打开并编辑这些文件。
为何需要更高压缩?
线性 DNG 是 DxO 为 DxO PureRAW 推荐的输出格式,因为它在保留最大后期编辑空间的同时,也与第三方 RAW 处理软件保持广泛兼容。 然而,即使采用 DNG 规范中内置的无损压缩,典型的线性 DNG 文件体积仍约为每百万像素 4 MB。 以一台 5000 万像素相机为例,单张图像的文件大小约为 200 MB。
显然,对这些文件进行更高效的压缩有着迫切的需求。
但在不牺牲画质的前提下,我们究竟能够压缩到何种程度?
从实际无损到感知无损
无损压缩对开发者与用户而言都是最令人安心的方案,因为它能够确保解压后的文件在数学意义上与原始文件逐位完全一致。 然而,这类算法在效率上存在固有局限,尤其当待压缩的信号中包含大量从人类视觉感知角度并无实际意义的信息时,这种局限便更加明显。
在 DxO PureRAW
我们在线性 DNG 文件中识别出两类从视觉感知角度并无实际意义的信息:
1. 过高的像素精度。 数码相机的 RAW 文件通常以每像素 12 位或 14 位编码,而我们的 DeepPRIME 处理流程输出为 16 位。 不过,图像始终会保留少量残余噪点——这是有意为之,旨在避免过度降噪带来的不自然“塑料感”。 如下文所述,信号中包含的噪点越多,其完整的数值精度就越缺乏实际意义。 去除这些未被有效利用的精度,正是动态范围压缩(DRC)的作用所在。
2. 纹理与颗粒的精确形态。 在实际应用中,噪点颗粒或细微纹理形态上的轻微差异几乎无法被人眼察觉。 对这些微观细节进行适度简化,是图像与视频压缩中的经典原则,而这一部分正由JPEG XL 编解码器负责实现。
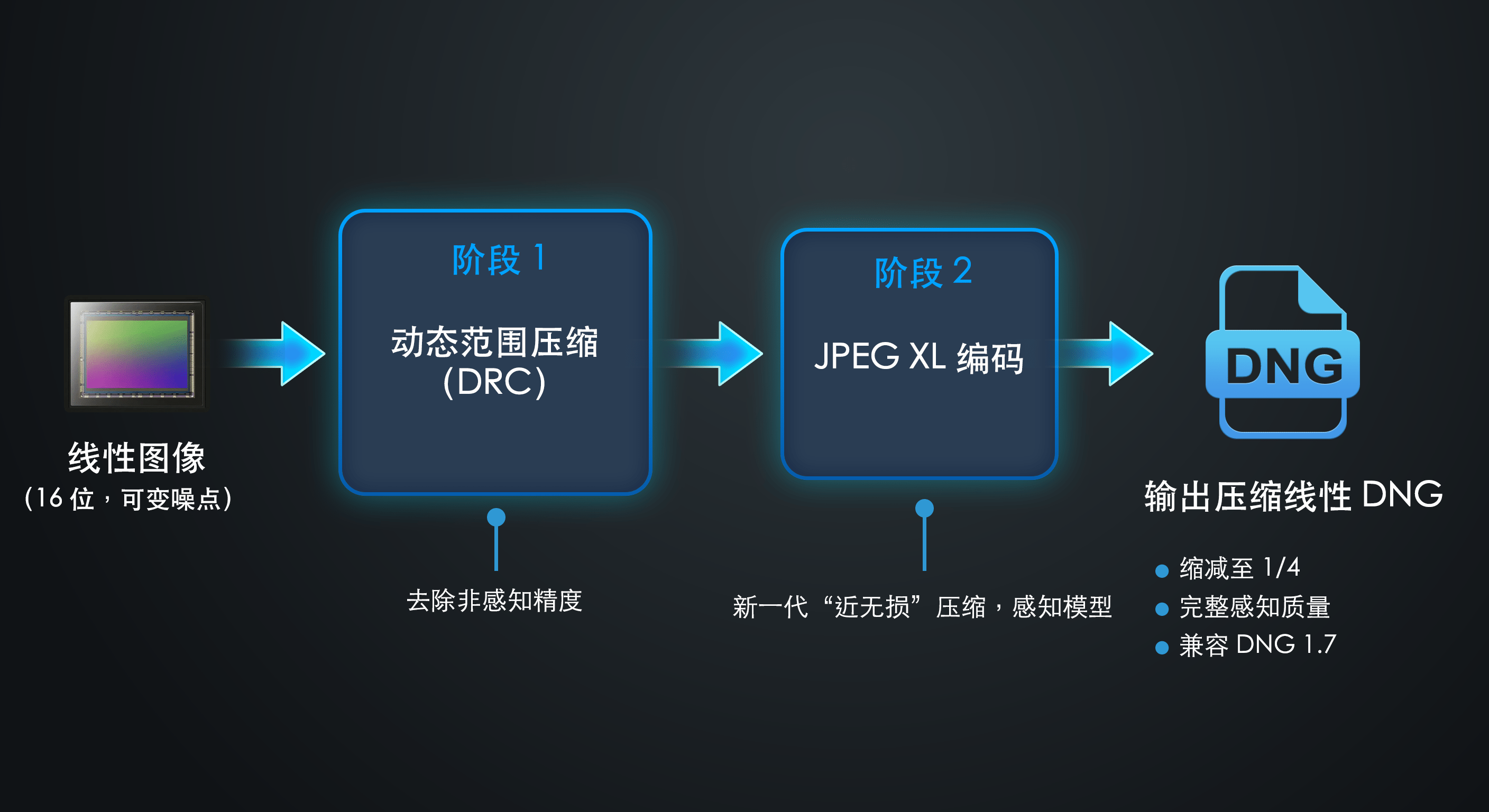
这两种技术均依托 DNG 标准机制实现,因此任何兼容 DNG 的软件都可以无缝打开生成的文件。 其中,DRC 通过 DNG 线性化表(Linearization Table)标签进行编码,而 JPEG XL 则作为 DNG 规范 1.7 版本中引入的一种压缩模式。 两者均已获得主流 RAW 处理应用的支持。
动态范围压缩
动态范围压缩(DRC)是音频信号处理领域中一项广为人知的技术。 压缩器通过应用非线性传递函数来缩小信号的动态范围:在音频领域,这意味着削弱较响的部分、提升较弱的部分,使信号能够在既定的比特预算内更高效地表达。 事实证明,这一原理同样非常适用于 RAW 数字图像。
为何 DRC 适用于 RAW 图像
数字图像会受到光子(散粒)噪声的影响,这是光本身的一种基本物理特性。 该噪声的标准差会随着信号强度的平方根而增长。
这一特性对线性图像的压缩具有重要影响:
- 在暗部区域,噪点水平极低,信号结构十分细腻。 此时每一位精度都可能承载真实而有用的信息——因此往往需要 14 位甚至 16 位的精度。
- 而在亮部区域,噪点相对较大, 可利用的信号精度远低于 14 位或 16 位所能表达的范围。 这些额外的比特实际上只是更精细地记录了噪点——其精度既没有实际必要,人眼也无法察觉。

正是这些在高光区域中、从视觉感知角度并无实际意义的高精度采样值,降低了无损压缩的效率:压缩算法仍必须逐位原样编码这些比特,而它们实际上并不承载任何有价值的信息。
- DRC 正是通过这一点发挥作用:在压缩之前,对线性像素值应用一种压扩函数——具体来说,是一条接近平方根曲线的变换。 从概念上看,这与方差稳定化变换密切相关:经过平方根变换后,噪点的标准差在整个色调范围内会趋于近似恒定。 由此,数值精度便能更合理地分配到最需要的区域——暗部拥有更多层级,高光则使用较少层级——同时又不会丢失任何在视觉上真正具有意义的信息。
在解压时,系统会通过 DNG 线性化表中存储的逆函数恢复原始的线性编码,这一过程完全符合 DNG 规范的设计方式。 整个流程对后续处理软件而言完全透明。
量化层级的数量采用了较为保守的设定,并在极端的编辑场景下进行了验证,例如大幅提升曝光并结合极端的阴影恢复,以确保在所有实际使用情境中都不会出现可见的量化伪影。
JPEG XL 压缩
在完成 DRC 处理后,经过预处理的图像将使用 JPEG XL 进行压缩。JPEG XL 是由 JPEG 委员会标准化的新一代图像编解码技术。
JPEG XL 为何优于传统 JPEG?
传统 JPEG 标准可追溯至 1992 年,其核心基于固定的 8×8 分块变换以及相对简单的熵编码机制。 这一方法在当时具有开创性意义,但以今天的标准来看,这种方法在压缩效率方面仍有相当大的提升空间。 JPEG XL 融合了二十多年来图像压缩研究的成果:
可变尺寸变换——从 2×2 到 256×256 的多种变换块尺寸,使编码器能够在平滑区域使用更大、更高效的块,而在边缘或细节区域使用更小、更精细的块。这样便能根据图像的局部内容自适应调整,而不再受限于单一固定网格。
感知优化的色彩空间——JPEG XL 的内部色彩表示以人类视觉系统为基础进行建模,从而能够更智能地将比特资源分配给对视觉感知最重要的图像信息。
先进的熵编码——采用更现代、效率显著提升的编码技术,相较传统方法能够从数据中提取更多冗余信息。
精密的预测与上下文建模——编码器在处理图像的过程中持续构建统计模型,捕捉细粒度的局部结构,从而减少需要实际存储的不可预测信息量。
原生高位深支持——与传统 JPEG 不同,JPEG XL 从设计之初便面向高位深内容,因此非常适合作为 RAW 影像处理流程中的压缩层。
我们在使用 JPEG XL 时采用近无损质量设置,这意味着编解码器引入的数学层面的信息损失极其微小——远低于任何真实图像中的噪点底限。 而与前置 DRC 的结合,正是实现高效压缩的关键所在:通过在交由 JPEG XL 处理之前先去除那些在视觉上并无意义的多余精度,我们为编解码器提供了一个本身就更易压缩的信号,从而无需让其做出任何可能损害画质的取舍。


为摄影忠实爱好者而造。