Automatische Staubkorrektur in digitalen Fotografien: Wie DxO PureRAW 6 mithilfe von Deep Learning Staubflecken erkennt und entfernt

DxO PureRAW 6 führt die automatische Stauberkennung und -entfernung ein: Ein einziger Klick identifiziert Staubflecken im gesamten Bild und beseitigt sie – ein mühsamer manueller Prozess wird so vollständig automatisiert. Die Funktion kombiniert ein hochmodernes neuronales Netz zur Objekterkennung mit DxOs bewährter Retusche-Engine.
Die wichtigsten Vorteile für Anwender
- Vollautomatischer Workflow. Stauberkennung und -entfernung lassen sich per Kontrollkästchen aktivieren. Stapelverarbeitung eines kompletten Shootings – jedes Bild wird makellos bereinigt.
- Einstellbare Empfindlichkeit. Ein Schieberegler ermöglicht es, zwischen dem Erfassen möglichst aller Flecken (hohe Empfindlichkeit) und der Vermeidung von Fehlern (niedrige Empfindlichkeit) abzuwägen.
(Trotzdem empfehlen wir, die Ausrüstung hin und wieder zu reinigen. 😉)
Das Problem
Kameras mit Wechselobjektiven neigen dazu, Staub auf dem Sensor oder den Objektiven anzusammeln. Diese Partikel erzeugen kleine, weiche Schatten in den Bildern, die besonders bei gleichmäßigen, homogenen Bereichen wie Himmel oder Studio-Hintergründen auffallen.
Fotografen lösen diese Probleme traditionell in der Nachbearbeitung mit Reparatur-, Klon- und Retusche-Werkzeugen. Bei stark betroffenen Bildern oder großen Bildmengen wird das schnell zur mühsamen Fleißarbeit.
DxO PureRAW 6 automatisiert diesen Prozess. Ein Erkennungsalgorithmus durchsucht das Bild nach Staubflecken, und ein Retusche-Algorithmus entfernt jeden einzelnen automatisch.
Darum ist Stauberkennung so anspruchsvoll
Auf den ersten Blick scheint Sensorstaub leicht zu beschreiben: kleine, dunkle, annähernd kreisförmige Flecken. Doch die scheinbare Einfachheit täuscht. Gleich mehrere Eigenschaften machen eine zuverlässige Erkennung überraschend schwierig.
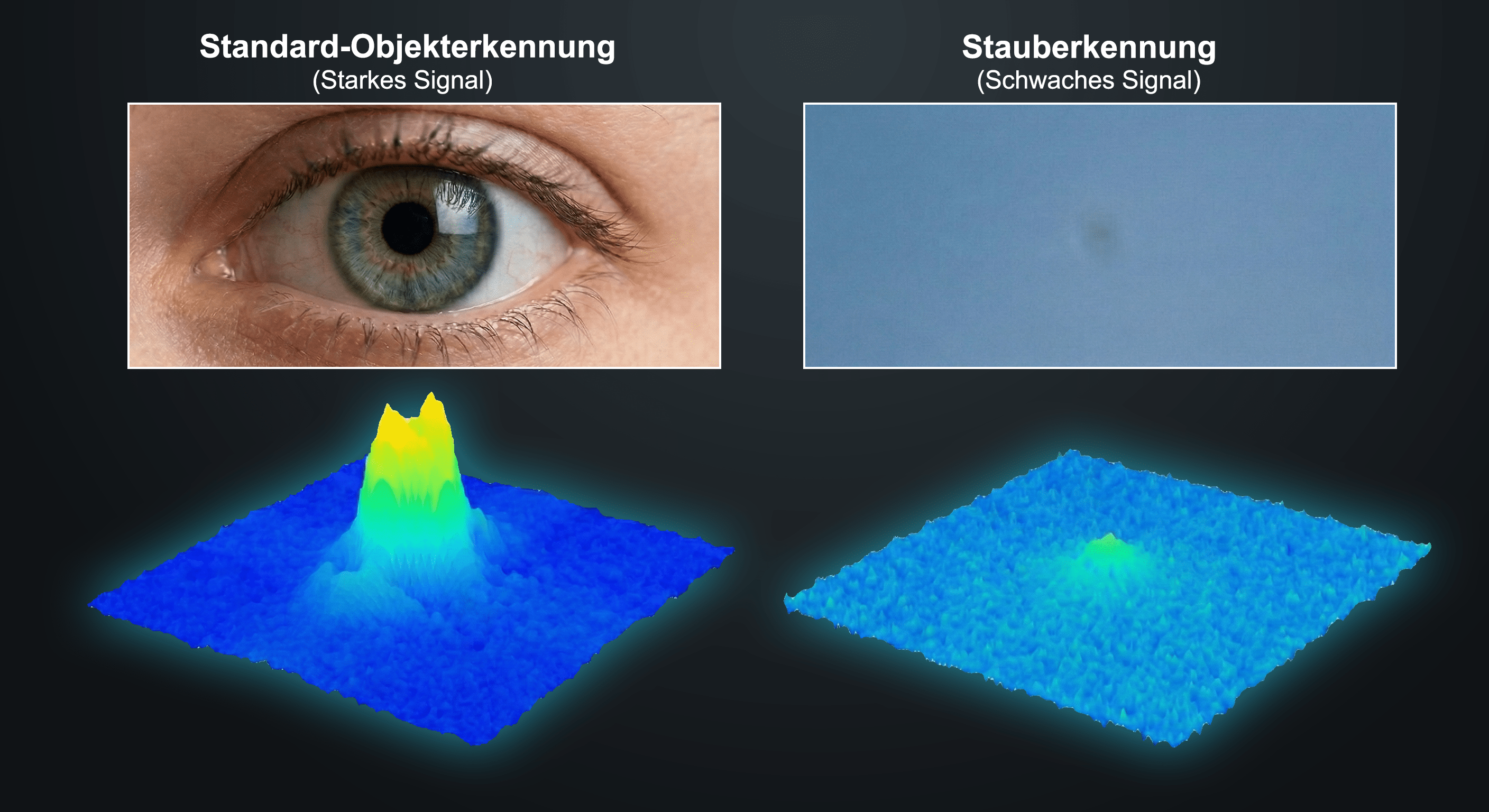
Extreme Subtilität. Die meisten Staubflecken schwächen nur einen kleinen Teil des einfallenden Lichts ab – oft lediglich 5 bis 20 Prozent. Es handelt sich um blasse Trübungen, nicht um deckende Flecken, und ihre Sichtbarkeit hängt stark vom darunterliegenden Bildinhalt ab.
Winzige räumliche Ausdehnung. In voller Auflösung umfasst ein typischer Staubfleck nur wenige Pixel – zu klein für universelle Objektdetektoren, die auf Menschen oder Fahrzeuge optimiert sind.
Keine ausgeprägte Struktur. Im Gegensatz zu Objekten, bei denen gängige Detektoren glänzen – ein Gesicht mit Augen, Nase und Mund; ein Auto mit Rädern und Fenstern –, bietet ein Staubfleck einem neuronalen Netz kaum Anhaltspunkte. Im Grunde ist er nur ein schwacher, dunkler Fleck.
Enorme Variabilität. Das Erscheinungsbild eines Staubflecks hängt von der Größe und Form des Partikels, seinem Abstand zur Sensoroberfläche, der Blende des Objektivs sowie von der Farbe und Helligkeit der zugrundeliegenden Szene ab. Manche Flecken sind scharfkantige Kreise, andere weiche, diffuse Halos. Einige erscheinen nahezu schwarz vor hellem Himmel, andere lassen sich kaum vom Rauschen unterscheiden. Die Vielfalt ist weit größer, als es ein flüchtiger Blick vermuten lässt. Die Abhängigkeit von Blende und Szene führt dazu, dass ein und dasselbe physische Partikel von Aufnahme zu Aufnahme ganz unterschiedlich aussehen kann.
Das Erkennungsmodell: RF-DETR
Das Herzstück der Funktion ist RF-DETR, eine transformerbasierte Architektur zur Objekterkennung. Wir haben mehrere Erkennungsarchitekturen getestet, darunter verschiedene Generationen CNN-basierter Modelle. RF-DETR wurde aus einer Kombination von Gründen ausgewählt:
Höchste Erkennungsgenauigkeit. RF-DETR erzielt Spitzenwerte in Standard-Benchmarks zur Objekterkennung und übertrifft viele bekannte Alternativen.
Mehrere Modellgrößen. Die Varianten Nano, Small, Medium, Large und XL erlauben es, den optimalen Kompromiss zwischen Genauigkeit und Rechenaufwand zu wählen. Wir haben die Variante Medium (33 Millionen Parameter) gewählt.
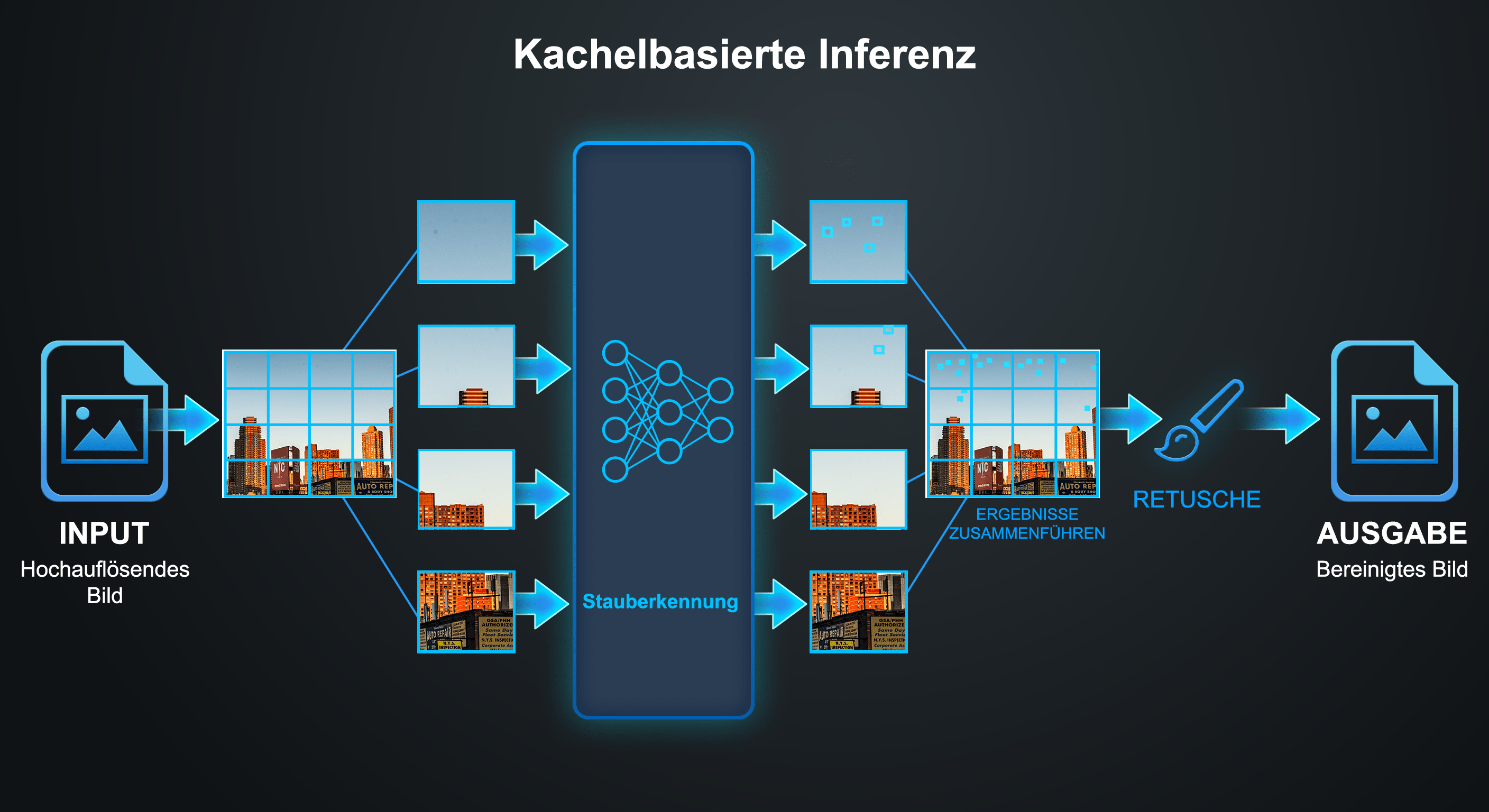
Auflösungsunabhängige Architektur. RF-DETR enthält keine vollständig verbundenen Schichten, die eine feste Eingangsauflösung erzwingen würden. Diese Flexibilität ist entscheidend für unsere gekachelte Inferenzstrategie: Das Bild wird in überlappende 512 × 512 Pixel große Kacheln unterteilt, und das Erkennungsmodell verarbeitet jede Kachel unabhängig. Anschließend werden die Ergebnisse über das gesamte Bild zusammengeführt.
In Standard-Benchmarks erkennt RF-DETR Dutzende Objektkategorien – Menschen, Fahrzeuge, Tiere, Möbel. Für unser Anwendungsbeispiel haben wir das Modell auf eine einzige Klasse trainiert: Staubfleck. Die Herausforderung liegt nicht in der Klassifikation, sondern in der Erkennung – dem Auffinden winziger, kontrastarmer Merkmale in einem riesigen Bild.
Trainingsdaten
Das Training eines zuverlässigen Staubdetektors erfordert, das Netzwerk mit einer sehr großen Zahl von Beispielen zu konfrontieren, die jede denkbare Kombination aus Staubform, Deckkraft, Unschärfe und Hintergrund abdecken.
Zunächst haben wir Tausende realer Fotografien mit echten Staubflecken gesammelt und sorgfältig von Hand gekennzeichnet. Dieser reale Datensatz deckt bereits eine große Vielfalt an Staubformen, -größen, Deckkraft, Unschärfe und Hintergründen ab – doch wir wollten noch weiter gehen.
Mit seiner Expertise in der Bild- und Signalverarbeitung hat unser Forschungsteam einen Staubsynthesizer entwickelt: einen kompakten Algorithmus, der einen Staubfleck erzeugt – von einem echten nicht zu unterscheiden – und ihn auf einen zufälligen fotografischen oder synthetischen Hintergrund montiert. Der Synthesizer modelliert die zentralen physikalischen Eigenschaften realer Staubpartikel: die unregelmäßige Tropfenform, die kanalweise Lichtabschwächung im linearen Farbraum, die Unschärfe an den Rändern sowie die optionale gerichtete Schattierung, die manche Partikel aufweisen. Jeder Parameter wird innerhalb sorgfältig kalibrierter Bereiche zufällig variiiert, die aus der statistischen Analyse realer Staubflecken abgeleitet wurden.
Dieser synthetische Ansatz gewährleistet eine gleichmäßige Verteilung von Staubeigenschaften und Hintergründen im gesamten Trainingsdatensatz und vermeidet so die Verzerrungen, die in manuell zusammengestellten Datensätzen unvermeidlich auftreten. Er stellt beispielsweise sicher, dass das Netzwerk genügend sehr schwache Flecken, genügend sehr kleine Flecken und genügend ungewöhnliche Hintergründe zu sehen bekommt – Kombinationen, die in einer rein realen Sammlung unterrepräsentiert wären.
Insgesamt hat unser Stauberkennungsnetzwerk im Laufe seines Trainings rund eine Million Staubflecken gesehen – eine Mischung aus realen und synthetischen Daten.

Für leidenschaftliche Fotografen.