デジタル写真のダスト自動補正:
DxO PureRAW 6 が
ディープラーニングで
ダストスポットを検出・除去する仕組み

DxO PureRAW 6 に、ダストの自動検出・除去機能が登場。ワンクリックで、画像全体のダストスポットを検出して消去することで、煩わしい手作業を自動化します。 この機能は、最先端のオブジェクト検出ニューラルネットワークと、DxO の実績ある修復エンジンを組み合わせたものです。
ユーザーにとっての主なメリット
- 完全に自動のワークフロー:ダストの検出と除去は、チェックボックス 1 つで完了します。 撮影データを一括処理すれば、すべての画像がクリーンな状態になります。
- 感度を調整可能:スライダを使って、あらゆるダストスポットを検出するか(高感度)、誤検出のリスクを抑えるか(低感度)を自由に調整できます。
(とは言っても、機材は定期的にクリーニングしましょう。 😉)
問題点
レンズ交換式カメラは、センサーやレンズにダストが付着しやすい傾向があります。 これらの微粒子は、画像に小さくぼんやりとしたシャドウを落とします。特に、空やスタジオの背景など、均一で滑らかな領域で目につきます。
フォトグラファーは、これまでは、このダストに撮影後の処理で対応し、修復、ヒール、レタッチブラシを使っていました。 ダストの多い画像や大量の画像を処理する場合、この作業はすぐに面倒なものになります。
DxO PureRAW 6 は、この処理を自動化します。 検出アルゴリズムが画像をスキャンしてダストスポットを検出し、修復アルゴリズムが各ダストスポットを自動的に除去します。
ダスト検出が難しい理由
一見すると、センサーダストは簡単に特定できそうに思えます。小さく、暗く、ほぼ円形のシミのようなものです。 ところが、このシンプルな見かけには落とし穴があります。 いくつかの特性が重なることで、検出は驚くほど難しくなります。
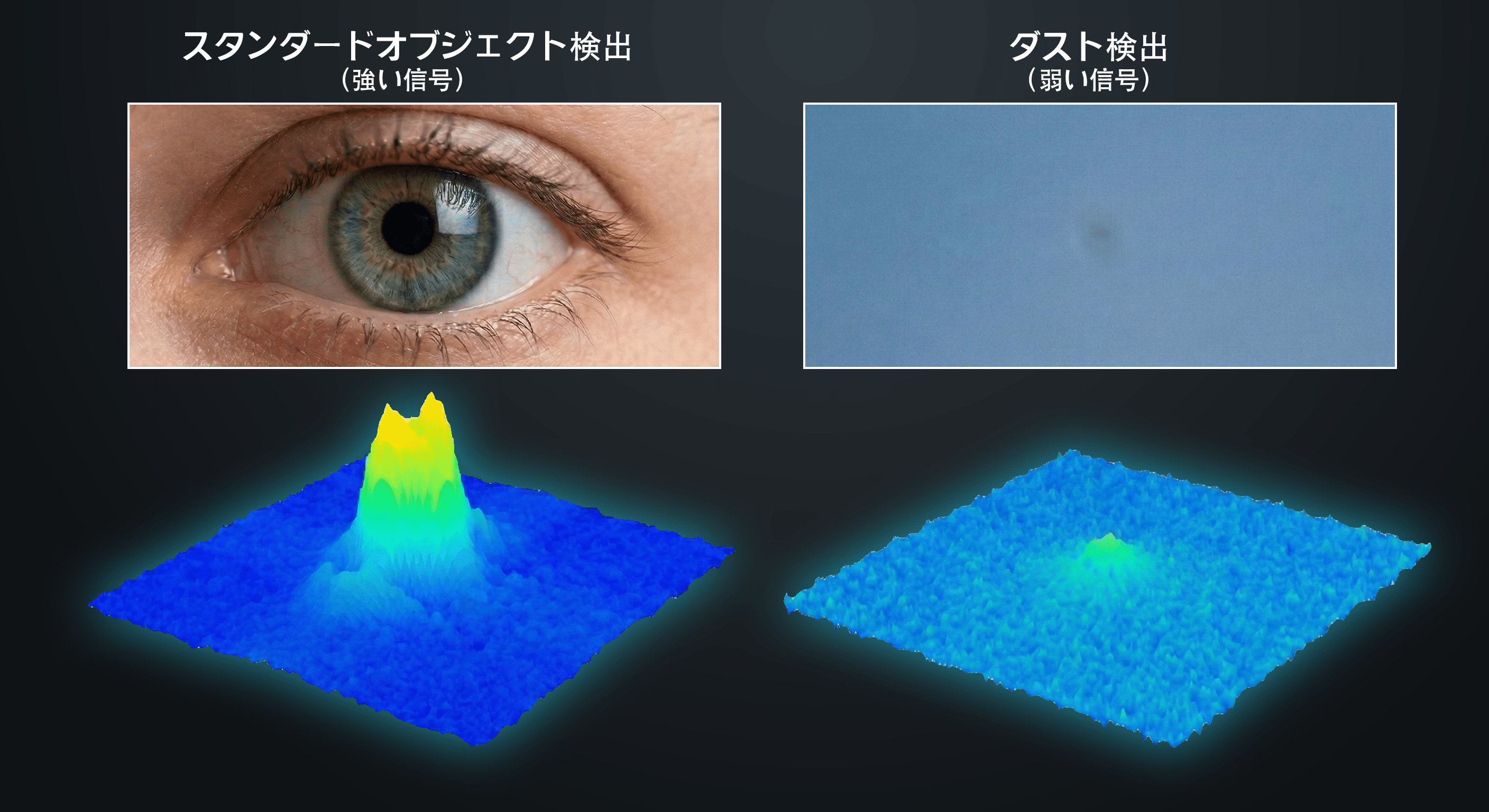
極めて微細:ほとんどのダストスポットが遮るのは、入射光のごくわずかな割合(多くの場合わずか 5 〜 20% 程度)だけです。 不透明な斑点ではなく、わずかな汚れであり、その視認性は背景となる画像に大きく左右されます。
非常に小さな空間的な広がり:一般的なダストスポットは、フル解像度では、わずか数ピクセル程度の大きさしかありません。人や車を検出するために最適化された汎用オブジェクト検出機能では、認識が困難なほど微細です。
特徴的な構造がない:主流の検出機能が得意とする被写体(目・鼻・口が写っている顔、ホイールや窓のある車など)とは異なり、ダストスポットにはニューラルネットワークが手がかりにできる要素がほとんどありません。 本質的に、かすかな暗いシミにすぎないのです。
膨大なバリエーション:ダストスポットの見え方は、粒子のサイズや形、センサー表面からの距離、レンズの絞り値、背景シーンの色や明るさによって変化します。 輪郭のはっきりした円形のものもあれば、ぼんやりとにじんだハロー状のものもあります。 明るい空に対してほぼ黒く見えるものもあれば、ノイズとほとんど区別がつかないものもあります。 ダストスポットは、想像するよりもはるかに多様です。 絞り値やシーンに依存するため、物理的に同じ粒子でも、写真ごとに見え方がまったく異なる可能性があります。
検出モデル:RF-DETR
この機能の中核を担うのが、トランスフォーマーベースのオブジェクト検出アーキテクチャ RF-DETR です。 DxO では、CNN ベースの複数世代のモデルを含む、さまざまな検出アーキテクチャを検証し、 以下の理由から RF-DETR を選択しました。
最先端の精度:RF-DETR は、標準的なオブジェクト検出ベンチマークでトップクラスのスコアを達成し、有名な多くの代替モデルを上回っています。
複数のモデルサイズ:Nano、Small、Medium、Large、XL のバリエーションが用意されており、精度と計算コストの最適なバランスを選択できます。 DxO は、Medium バリエーション(3,300万パラメータ)採用しました。
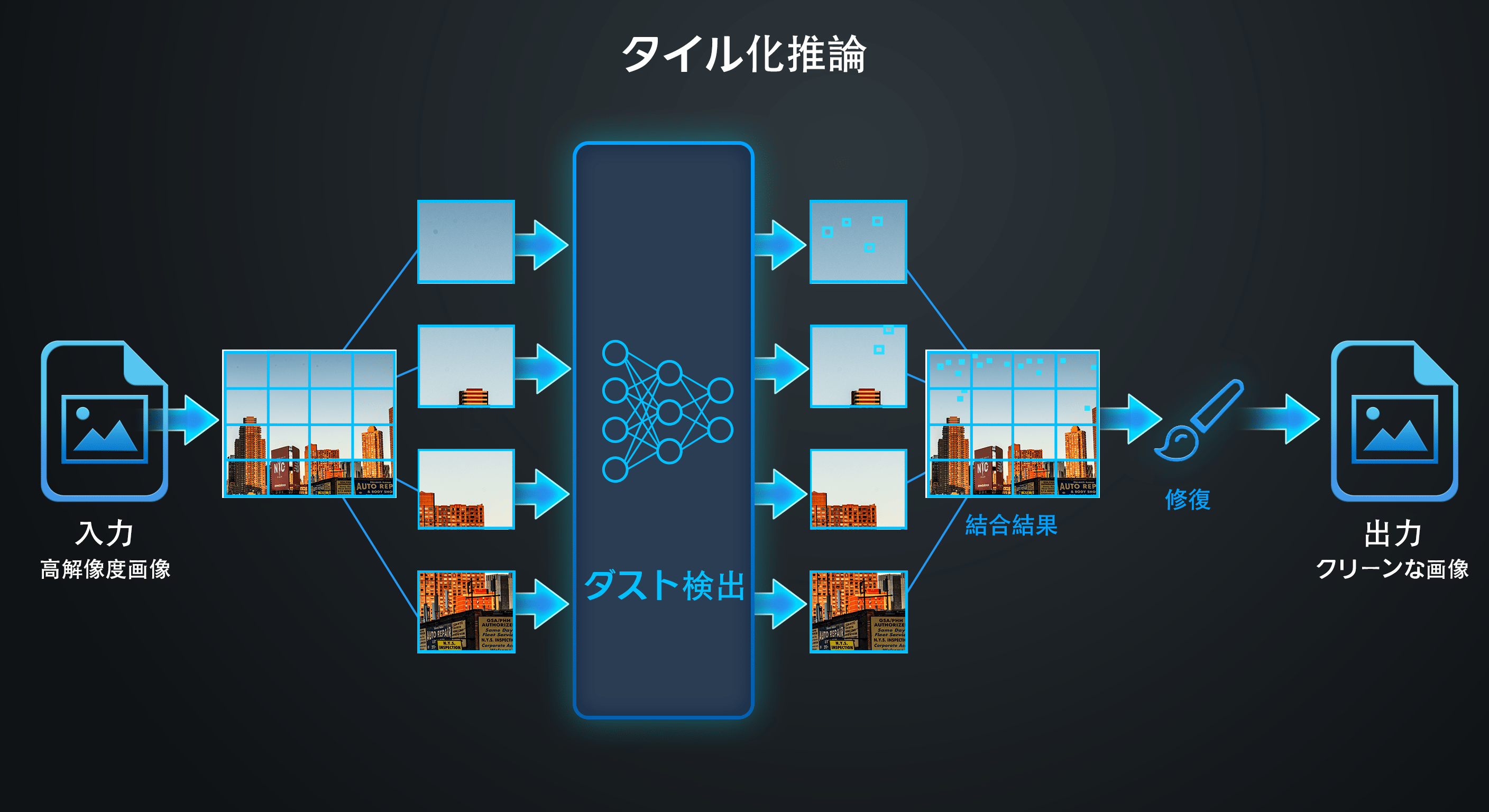
解像度に依存しないアーキテクチャ:RF-DETR には、入力解像度を固定する全結合レイヤーが含まれていません。 この柔軟性は、DxO のタイル化推論戦略において重要です。画像を 512×512 ピクセルのオーバーラップするパッチに分割し、各パッチに対して検出モデルが個別に実行されます。 その結果は、フルイメージ全体で統合されます。
標準的なベンチマークでは、RF-DETR は、人、車、動物、家具など、数十のオブジェクトカテゴリーを検出します。 DxO では、ダストスポットという単一クラスのみを認識するように同モデルを再トレーニングしました。 課題は、分類ではなく検出、つまり広大な画像の中から微小で低コントラストな特徴を見つけ出すことです。
トレーニングデータ
信頼性の高いダスト検出機能をトレーニングするには、ダストの形、不透明度、ブラー、背景のあらゆる組み合わせを網羅した、膨大な数のサンプルをネットワークに学習させる必要があります。
まず、DxO は、実際にダストスポットがある数千枚の写真を収集し、すべてを手作業で丁寧にラベル付けしました。 この実写データセットだけでも、多様なダストの形、サイズ、不透明度、ブラーの具合、背景を幅広くカバーしていますが、DxO はさらに先を目指しました。
画像と信号処理に関する専門知識を活かし、DxO の研究チームは、ダストシンセサイザーを開発しました。これは、実物と見分けがつかないダストスポットを生成し、ランダムな写真または合成背景に合成する、コンパクトなアルゴリズムです。 このシンセサイザーは、実際のダストの主要な物理的特性(不規則なシミの形、線形空間におけるチャネルごとの光の減衰、エッジを柔らかくするブラー、一部の粒子が示す方向性のあるシェーディングなど)をモデル化します。 すべてのパラメータは、実際のダストスポットの統計分析から導き出された、慎重にキャリブレーションされた範囲内で無作為に選択されます。
この合成アプローチにより、トレーニングセット全体でダストの特性と背景が均等に分布し、手動で収集したデータセットでは避けられない偏りを解消します。 たとえば、非常にかすかなスポット、非常に小さなスポット、通常とは異なる背景など、実写画像だけでは不足しがちな組み合わせをネットワークに十分学習させることができます。
DxO のダスト検出ネットワークは、トレーニングの過程で、実写と合成を合わせて約 100 万個のダストスポットを学習しています。

写真を愛するフォトグラファーのために。